Building a Python ecosystem for efficient and reliable development
Tl;dr: This blog post describes how we developed an efficient, reliable Python ecosystem using Pants, an open source build system, and solved the challenge of managing Python applications at a large scale at Coinbase.

By The Coinbase Compute Platform Team
Python is one of the most frequently used programming languages for data scientists, machine learning practitioners, and blockchain researchers at Coinbase. Over the past few years, we have witnessed a growth of Python applications that aim to solve many challenging problems in the cryptocurrency world like Airflow data pipelines, blockchain analytics tools, machine learning applications, and many others. Based on our internal data, the number of Python applications has almost doubled since Q3, 2022. According to our internal data, today there are approximately 1,500 data processing pipelines and services developed with Python. The total number of builds is around 500 per week at the time of writing. We foresee an even wider application as more Python centric frameworks (such as Ray, Modin, DASK, etc.) are adopted into our data ecosystem.
Choosing the right tool
Engineering success comes largely from choosing the right tools. Building a large-scale Python ecosystem to support our growing engineering requirements could raise some challenges, including using a reliable build system, flexible dependency management, fast software release, and consistent code quality check. However, these challenges can be combated by integrating Pants, a build system developed by Toolchain labs, into the Coinbase build infrastructure. We chose this as the Python build system for the following reasons:
- Pants is ergonomic and user-friendly,
- Pants understands many build-related commands, such as “test”, “lint”, “fmt”, “typecheck”, and “package”
- Pants was designed with real-world Python use as a first-class use-case, including handling third party dependencies. In fact, parts of Pants itself is written in Python (with the rest written in Rust).
- Pants requires less metadata and BUILD file boilerplate than other tools, thanks to the dependency inference, sensible defaults and auto-generation of BUILD files. Bazel requires a huge amount of handwritten BUILD boilerplate.
- Pants is easy to extend, with a powerful plugin API that uses idiomatic Python 3 async code, so that users can have a natural control flow in their plugins.
- Pants has true OSS governance, where any org can play an equal role.
- Pants has a gentle learning curve. It has much less friction than other tools. The maintenance cost is moderate thanks to the one-click installation experience of the tool and simple configuration files.
Previous problems
Python is one of the most popular programming languages for machine learning and data science applications. However, prior to adopting the Python-first build system, Pants, our internal investment in the Python ecosystem was low in comparison to that of Golang and Ruby — the primary choice for writing services and web applications at Coinbase.
According to the usage statistics of Coinbase’s monorepo, Python today accounts for only 4% of the usage because of lack of build system support. Before 2021, most of the Python projects were in multiple repositories without a unified build infrastructure — leading to the following issues:
- Challenges with code sharing: The process for an engineer to update a shared library was complex. Changes made to the code were published to an internal PyPI server before being proven to be more stable. A library that was upgraded to a new version, but had not undergone enough testing, could potentially break the dependee that consumed the library without a pinned version.
- Lack of streamlined release process: Code change often required complicated cross-repository updates and releases. There was no automatic workflow to carry out the integration and staging tests for the relevant changes. The lack of coherent observability and reliability imposed a tremendous engineering overhead.
- Inconsistent development experiences: Development experience varied a lot as each repository had its own way of virtual environment setup, code quality check, build and deployment etc.
Building PyNest for data organization
We decided to build PyNest — a new Python “monorepo” for the data organization at Coinbase. It is not our intention for PyNest to be use as a monorepo for the entire company, but rather that the repository is used for projects within the data organization.
- Building a company-wide monorepo requires a team of elites. We do not have enough crew to reproduce the success stories of monorepos at Facebook, Twitter, and Google.
- Python is primarily used within the data org in the company. It is important to set the right scope so that we can focus on data priorities without being distracted by ad hoc requirements. The PyNest build infrastructure can be reused by other teams to expedite their Python repositories.
- It is desirable to consolidate mutually dependent projects (see the dependency graph for ML platform projects) into a single repository to prevent inadvertent cyclic dependencies.
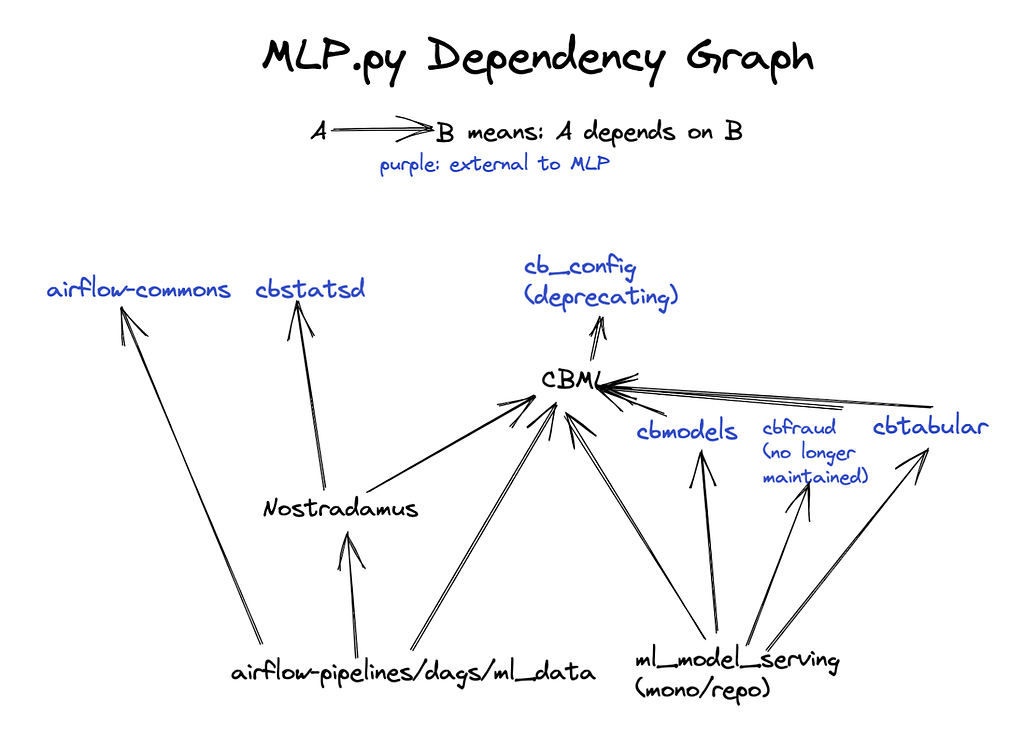
Figure 1. Dependency graph for machine learning platform (MLP) projects.
- Although monorepo promised a new world of productivity, it has been proven not to be a long term solution for Coinbase. The Golang monorepo is a lesson, where problems emerged after a year of usage such as sprawling codebase, failed IDE integrations, slow CI/CD, out-of-date dependencies, etc.
- Open source projects should be kept in individual repositories.
The graph below shows the repository architecture at Coinbase, where the green blocks indicate the new Python ecosystem we have built. Inter-repository operability is achieved by serving layers including the code artifacts and schema registry.
Figure 2. Repository architecture at Coinbase
PyNest repository structure
# third-party dependencies
# third-party dependencies
├── 3rdparty
│ ├── dependency1
│ │ ├── BUILD
│ │ ├── requirements.txt
│ │ └── resolve1.lock # lockfile
│ │
│ └── dependency2
│ │ ├── BUILD
│ │ ├── requirements.txt
│ │ └── resolve2.lock
...
│
# shared libraries
├── lib
│
# top level project folders
├── project1 # project name
│ ├── src
│ │ └── python
│ │ ├── databricks
│ │ │ ├── BUILD
│ │ │ ├── OWNERS
│ │ │ ├── gateway.py
│ │ │ ...
│ │ └── notebook
│ │ ├── BUILD
│ │ ├── OWNERS
│ │ ├── etl_job.py
│ │ ...
│ └── test
│ └── python
│ ├── databricks
│ │ ├── BUILD
│ │ ├── gateway_test.py
│ │ ...
│ └── notebook
│ ├── BUILD
│ ├── etl_job_test.py
│ ...
├── project2
...
│
# Docker files
├── dockerfiles
│
# tools for lint, formatting, etc.
├── tools
│
# Buildkite CI workflow
├── .buildkite
│ ├── pipeline.yml
│ └── hooks
│
# Pants library
├── pants
├── pants.toml
└── pants.ci.toml
Figure 3. Pynest repository structure
The following is a list of the major elements of the repository and their explanations.
1. 3rdparty
Third party dependencies are placed under this folder. Pants will parse the requirements.txt files and automatically generate the “python_requirement” target for each of the dependencies. Multiple versions of the same dependency are supported by the multiple lockfiles feature of Pants. This feature makes it possible for projects to have conflicts in either direct or transitive dependencies. Pants generates lockfiles to pin every dependency and ensure a reproducible build. More explanations of the pants multiple lock is in the dependency management section.
2. Lib
Shared libraries accessible to all the projects. Projects within PyNest can directly import the source code. For projects outside PyNest, the libraries can be accessed via pip installing the wheel files from an internal PyPI server.
3. Project folders
Individual projects live in this folder. The folder path is formatted as “{project_name}/{src or test}/python/{namespace}”. The source root is configured as “src/python” or “test/python”, and the underneath namespace is used to isolate the modules.
4. Code owner files
Code owner files (OWNERS) are added to the folders to define the individuals or teams that are responsible for the code in the folder tree. The CI workflow invokes a script to compile all the OWNERS files into a CODEOWNERS file under “.github/”. Code owner approval rule requires all pull requests to have at least one approval from the group of code owners before they can be merged.
5. Tools
Tools folder contains the configuration files for the code quality tools, e.g. flake8, black, isort, mypy, etc. These files are referenced by Pants to configure the linters.
6. Buildkite workflow
Coinbase uses Buildkite as the CI platform. The Buildkite workflow and the hook definitions are defined in this folder. The CI workflow defines the steps such as
- Check whether dependency lockfiles need updating.
- Execute lints and code quality tools.
- Build source code and docker images.
- Runs unit and integration tests.
- Generates reports of code coverages.
7. Dockerfiles
Dockerfiles are defined in this folder. The docker images are built by the CI workflow and deployed by Codeflow — an internal deployment platform at Coinbase.
8. Pants libraries
This folder contains the Pants script and the configuration files (pants.toml, pants.ci.toml).
This article describes how we build PyNest using the Pants build system. In our next blog post, we will explain dependency management and CI/CD.
![]()
Building a Python ecosystem for efficient and reliable development was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
1 September 2022 14:02